会議が終わるたびに、誰が議事録をまとめるかで牽制し合う。あるいは、録音データを何度も聞き直しながら、数時間かけてテキストに書き起こす。ビジネスの現場において、こうした光景は決して珍しくありません。
近年、AIを活用した「文字起こしAIツール」や議事録自動化サービスが数多く登場しています。確かにこれらは便利ですが、いざ導入しようとすると「月額費用が高額で稟議が通らない」「自社特有の議事録フォーマットに合わせてくれない」「セキュリティの観点からクラウドサービスへの音声アップロードに制限がある」といった壁に直面するケースが報告されています。
では、高額な専用ツールを契約できなければ、手作業の苦行を続けるしかないのでしょうか。
答えは「ノー」です。専門家の視点から言えば、汎用的なAIモデルのAPIを組み合わせることで、低コストかつ柔軟な「自分専用の議事録自動化パイプライン」を構築することが十分に可能です。本記事では、ITスキルが一般的な実務担当者でも実践できる、AI議事録の自作チュートリアルをステップバイステップで解説します。
このチュートリアルのゴールと自動化の全体像
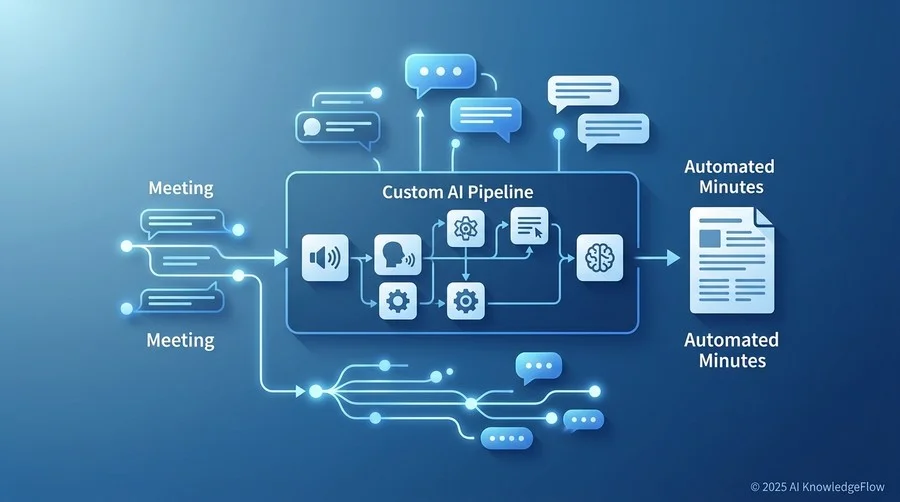
本チュートリアルの目的は、既存のパッケージサービスに依存せず、最新のAI技術を組み合わせて「録音から要約・タスク抽出まで」を一気通貫で行う仕組みを理解し、実際に手を動かして構築体験を得ることにあります。
なぜ専用ツールではなく「パイプライン」を自作するのか
議事録用途では、OpenAIやAnthropicの公式ドキュメントで現在利用可能な最新系の音声・言語モデルを使うのが適切です。旧世代名の固定的な前提は避けてください。つまり、私たちが直接これらの基盤モデルのAPI(Application Programming Interface)を叩く仕組みを作れば、SaaSの中抜きコストを抑え、従量課金のみで高品質な処理が可能になるというわけです。
また、自作の最大のメリットは「カスタマイズ性」にあります。営業の商談、開発の定例会議、経営層の戦略会議など、会議の性質によって求められる議事録の粒度は異なります。パイプラインを自作すれば、AIへの指示(プロンプト)を調整するだけで、自社に最適なフォーマットを自由自在に出力させることができます。
達成できること:文字起こしからタスク抽出までの自動化
このチュートリアルを通じて構築する自動化フローは、以下の4つのステップで構成されます。
- 音声データの準備:スマートフォンやWeb会議ツールで録音した音声ファイルを用意する。
- 文字起こし(Speech-to-Text):音声認識AIを用いて、音声を高精度なテキストに変換する。
- 構造化要約(Text-to-Text):テキスト化された膨大な会話から、決定事項やネクストアクションを抽出する。
- 共有と運用:生成された議事録をチームのツールに連携し、人間が最終確認を行う。
それでは、さっそく環境構築から始めていきましょう。
環境構築:必要なツールとセットアップ
「自分でシステムを作る」と聞くと、複雑なプログラミング環境の構築を想像するかもしれません。しかし、現在はブラウザ上で完結する便利なツールが揃っています。
録音データを準備するための基本設定
まずは、実行環境として「Google Colaboratory(通称:Colab)」を利用します。これはGoogleが提供する無料のクラウド実行環境で、ブラウザを開くだけでPythonというプログラミング言語を動かすことができます。PCに特別なソフトをインストールする必要はありません。
Googleアカウントにログインした状態でColabにアクセスし、「ノートブックを新規作成」をクリックするだけで準備は完了です。このノートブック上で、後述するコードを「コピー&ペーストして実行ボタンを押すだけ」でAIを操作できます。
文字起こしエンジン(Whisper)の選択肢
音声をテキストに変換するエンジンとして、OpenAIが開発した「Whisper」を利用します。Whisperは非常に精度の高い音声認識モデルであり、会議特有の雑音や複数人の会話、さらには専門用語が混ざる日本語の音声でも、文脈を補完しながら正確に文字起こしを行う能力を持っています。
OpenAIの公式ドキュメントで現在案内されている音声認識API・モデルを利用してください。実装例は『最新の音声認識API』として記述するのが安全です。OpenAIの公式開発者プラットフォーム(platform.openai.com)にアクセスし、アカウントを作成して「APIキー」を取得します。APIキーは、AIを利用するための「パスワード付きの入場券」のようなものです。
※APIの利用にはクレジットカードの登録が必要ですが、使った分だけ支払う従量課金制です。詳細な料金体系については、公式サイトをご確認ください。
要約用AI(GPT-4o/Claude 3.5)の準備
文字起こしされたテキストを要約するためには、大規模言語モデル(LLM)のAPIを使用します。現在、ビジネス用途で高い性能を発揮する代表的なモデルとして、以下の2つが挙げられます。
OpenAI公式の現行モデル一覧に従い、最新の利用可能モデルを選んでください。構造化出力や長文処理は、各モデルとAPIの対応状況を公式ドキュメントで確認してください。
Anthropic公式ドキュメントで現在利用可能な最新のClaude系モデルを前提に記述してください。公式ドキュメントによれば、数十万トークン級のコンテキストに対応しており、極めて長い議事録の処理にも適しています。
本チュートリアルでは、OpenAI公式ドキュメントで現在利用可能な最新のモデルを前提に進めます。
Step 1:高精度な文字起こしを実行する
環境が整ったら、実際に音声ファイルをテキストに変換してみましょう。
Whisperを使用した音声データのテキスト化
Google Colabのセル(入力欄)に、以下のPythonコードを貼り付けます。OpenAI公式ドキュメントで案内されている現在の音声認識APIに合わせたコードを使用してください。
!pip install openai
from openai import OpenAI
# 取得したAPIキーをここに入力します
client = OpenAI(api_key="sk-your-api-key-here")
# 録音ファイル(例:meeting.mp3)をColabにアップロードして指定します
audio_file = open("meeting.mp3", "rb")
# Whisper APIを呼び出し
transcript = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
# 結果を表示
print(transcript.text)
操作はこれだけです。Colabの画面左側にあるフォルダアイコンから音声ファイルをアップロードし、ファイル名をコードと合わせます。そして再生ボタン(実行ボタン)を押すと、数十秒から数分で、驚くほど正確な文字起こしテキストが出力されます。
長い会議データ(1時間以上)を処理するコツ
ここで一つ、実務上の壁にぶつかることがあります。OpenAIのWhisper APIには、一度に送信できるファイルサイズに制限(一般的に25MBまで)があります。1時間を超えるような高音質の録音データは、この制限に引っかかってエラーになるケースが報告されています。
この課題を解決するためには、音声ファイルを細かく分割(チャンク化)して順番に処理する必要があります。例えば、pydubというPythonのライブラリを使えば、音声を10分ごとのパーツに切り分け、それぞれをWhisperで文字起こしした後に、結合して1つの長いテキストにまとめることが可能です。少しコードは長くなりますが、こうした「前処理の工夫」が、安定した自動化パイプラインの構築には不可欠です。
Step 2:決定版「議事録構造化要約」プロンプトの設計
文字起こしが完了したら、次はそのテキストを「実用的な議事録」に変換します。ここで重要になるのが、AIへの指示文である「プロンプト」の設計です。
単なる要約で終わらせない「構造化」の指定
「以下のテキストを要約してください」という単純な指示では、AIは会話の表面的なあらすじをまとめるだけで、ビジネスで使える議事録にはなりません。実務で求められるのは、情報が整理された「構造化」されたデータです。
構造化された出力が必要な場合は、各社の公式ドキュメントで案内されている構造化出力・スキーマ指定などの機能を優先し、必要最小限の指示で制御してください。多くのプロジェクトでは、以下のようなプロンプトのフレームワークが活用されています。
# 指示
あなたは優秀なプロジェクトマネージャーです。
以下の【会議の文字起こしデータ】を読み込み、指定された【出力フォーマット】に厳密に従って議事録を作成してください。
# 出力フォーマット
## 1. 会議の概要
- 目的:
- 主な議題:
## 2. 決定事項
(会議内で明確に合意された事項を箇条書きで記載)
## 3. 保留・検討事項
(結論が出ず、次回以降に持ち越しとなった事項)
## 4. ネクストアクション(To-Do)
- [ ] アクション内容(担当者名:期限)
# 会議の文字起こしデータ
(ここにWhisperでテキスト化したデータを挿入)
決定事項・保留事項・ネクストアクションを抽出する
B2Bの会議において最も重要なのは「誰が」「いつまでに」「何を」するのかというネクストアクションの明確化です。上記のプロンプトのように、出力フォーマットの項目を明示的に指定することで、GPT-4oやClaude 3.5は膨大な会話の文脈から、タスクの割り振りや期限に関する発言を高精度に拾い上げ、整理してくれます。
特に最新のGPT-4oは、指示された構造に従う能力が非常に高いため、フォーマット崩れを最小限に抑えることができます。
Step 3:運用フローへの組み込みと共有
見事な議事録が生成されても、それが個人のパソコンの中に眠っていては意味がありません。チーム全体で活用するための運用フローを設計しましょう。
NotionやSlackへの自動投稿(簡易版)
最初は、生成されたテキストを手動でコピーして社内チャットやドキュメントツールに貼り付ける運用でも十分な業務効率化になります。しかし、さらに一歩進めるなら、iPaaS(Integration Platform as a Service)と呼ばれる連携ツールを活用します。
例えば、「Make」や「Zapier」といったツールを使えば、「Googleドライブに音声ファイルが保存されたら、自動でWhisper APIとGPT-4o APIを呼び出し、完成した議事録をSlackの特定チャンネルとNotionのデータベースに自動投稿する」という一連の流れを、ノーコードで構築できます。
チームへのフィードバックと修正のルール化
AIを業務に組み込む際、決して忘れてはならない原則があります。それは「AIの出力結果を人間が最終確認する(Human-in-the-Loop)」というプロセスです。
AIは非常に優秀ですが、文脈を誤解したり、存在しない事実をもっともらしく書き出したりするハルシネーション(幻覚)を完全にゼロにすることはできません。そのため、「AIが作成した議事録のドラフト(下書き)をSlackに投稿し、参加者がざっと目を通して修正・承認する」という運用ルールをチーム内で合意しておくことが、トラブルを防ぐ鍵となります。
また、企業でAPIを利用する際のセキュリティ上の注意点として、API経由で送信されたデータがAIモデルの学習に利用されない設定(オプトアウト)になっているか、公式ドキュメントで必ず確認するようにしてください。
トラブルシューティングと精度向上のためのQA
実際にこのパイプラインを運用し始めると、いくつかの実務的な課題に直面するはずです。ここでは代表的な疑問とその解決策を提示します。
専門用語や固有名詞が誤変換される場合の対策
Q: 自社独自のプロジェクト名や、業界特有の専門用語が、文字起こしの段階で全く別の言葉に誤変換されてしまいます。どうすればよいですか?
A: Whisper APIには、特定の単語を認識しやすくするための「プロンプトパラメータ(初期プロンプト)」を渡す機能があります。APIを呼び出す際に、自社の専門用語や参加者の名前をカンマ区切りで事前知識として与えることで、誤変換を大幅に減らすことができます。
また、要約を担当するGPT-4o側のプロンプトに「用語辞書」を組み込み、「Aという誤変換があった場合は、Bという専門用語に読み替えて要約せよ」と指示するアプローチも非常に有効です。
複数人の発話者が混ざる場合の識別方法
Q: 誰が発言したのか(Aさん、Bさん)を自動で識別して議事録に残すことはできますか?
A: 音声から話者を識別する技術を「Diarization(話者分離)」と呼びます。現状、標準のWhisper API単体では、話者の自動識別機能は提供されていません。オープンソースのPyannoteなどの話者分離ライブラリとWhisperを組み合わせる高度な手法もありますが、構築のハードルが上がります。
実務的で手軽な解決策としては、要約用プロンプトに「文脈や発言内容から、進行役、決裁者、担当者などの役割を推測し、可能な範囲で発言者を補って要約してください」と指示する方法があります。完璧ではありませんが、会話の流れからAIが「これは上司の指示である」といった文脈を読み取り、分かりやすく整理してくれます。
まとめ:自社に最適な議事録自動化の仕組みを構築するために
本記事では、専用ツールに頼らず、汎用AIモデルを活用して議事録の自動化パイプラインを構築する実践的なアプローチを解説しました。Google ColabやAPIを活用することで、低コストでカスタマイズ性の高い仕組みを自分の手で作り上げることが可能です。
まずは、身近な定例会議などの録音データを使って、スモールスタートでPoC(概念実証)を行ってみることをおすすめします。実際に手を動かすことで、AIの得意なこと、苦手なことが肌で理解できるはずです。
一方で、この仕組みを全社規模で展開しようとした場合、新たな課題も生じます。
「社員全員が使えるような使いやすい社内UI(画面)をどう開発するか」
「社内のActive Directoryと連携した権限管理をどう実現するか」
「より厳密なセキュリティ要件やコンプライアンス基準をどう満たすか」
個人や単一チームでの利用を超えて、全社的な業務効率化のインフラとしてAI導入を検討する段階に入った場合は、自作のパイプラインだけでは対応が難しくなるケースが一般的です。
自社への本格的な適用を検討する際は、専門的な知見を持つパートナーへの相談で、導入リスクを軽減し、既存システムとのシームレスな連携を実現できます。個別のセキュリティ要件や業務フローに応じたアーキテクチャ設計、システム構築のROI(費用対効果)を評価するためにも、具体的な導入条件を明確化する商談や見積もりの機会を設けることで、より確実で効果的なAI導入が可能になります。
ぜひ、今回構築したパイプラインでの検証結果をベースに、次のステップへと進めてみてください。
コメント